Generate realistic synthetic tabular data with TabPFN in seconds.
The Data Generation capability extends TabPFN’s unsupervised modeling system to create realistic synthetic tabular datasets. By modeling feature dependencies and joint probability distributions, TabPFN can generate new samples that follow the same statistical structure as your original data - useful for augmentation, simulation, and masking sensitive data.
Then, use the TabPFNUnsupervisedModel with a TabPFN classifier and regressor model to generate new data:
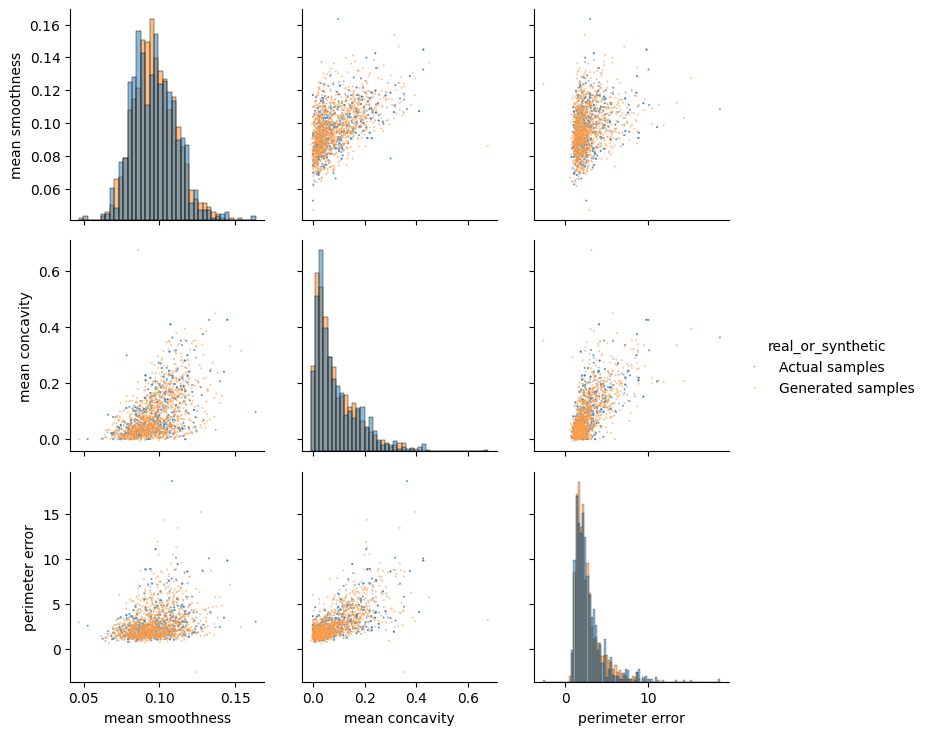
from tabpfn_extensions import unsupervisedfrom tabpfn_extensions.unsupervised import experimentsfrom sklearn.datasets import load_breast_cancerimport torchfrom tabpfn_extensions import TabPFNClassifier, TabPFNRegressor# Load and prepare breast cancer datasetdf = load_breast_cancer(return_X_y=False)X, y = df["data"], df["target"]feature_names = df["feature_names"]# Initialize TabPFN modelsmodel_unsupervised = unsupervised.TabPFNUnsupervisedModel( tabpfn_clf=TabPFNClassifier(), tabpfn_reg=TabPFNRegressor())# Select features for synthetic data generation# Example features: [mean texture, mean area, mean concavity]feature_indices = [4, 6, 12]# Run synthetic data generation experimentexperiment = unsupervised.experiments.GenerateSyntheticDataExperiment( task_type="unsupervised")results = experiment.run( tabpfn=model_unsupervised, X=torch.tensor(X), y=torch.tensor(y), attribute_names=feature_names, temp=1.0, # Temperature parameter for sampling n_samples=X.shape[0] * 2, # Generate twice as many samples as original data indices=feature_indices,)
The data generation process leverages the same probabilistic modeling used in TabPFN’s unsupervised mode:
Each feature is modeled conditionally on the others.
The chain rule of probability is used to estimate the full joint distribution.
New samples are drawn using the learned conditional dependencies, controlled by a temperature parameter (temp) that influences variability and diversity.
By default, each feature is conditioned on all other features. If you have prior knowledge about the causal structure of your data, you can pass a Directed Acyclic Graph (DAG) to generate_synthetic_data via the dag parameter. This restricts each feature’s conditioning set to its declared parents, so generated samples respect your domain knowledge about feature dependencies.The dag is a dict[int, list[int]] mapping each feature index to the list of its parent feature indices. Features are generated in topological order (parents before children). Features with no declared parents are generated marginally first. Partial DAGs are supported — features not present as keys fall back to the default all-features conditioning.
import torchfrom sklearn.datasets import load_winefrom tabpfn_extensions import TabPFNClassifier, TabPFNRegressor, unsuperviseddf = load_wine(return_X_y=False)X, y = df["data"], df["target"]attribute_names = df["feature_names"]# Build a DAG expressed as feature names, then convert to integer indiceswine_dag_by_name = { "alcohol": [], "malic_acid": [], "ash": ["magnesium"], "alcalinity_of_ash": ["ash", "magnesium"], "magnesium": [], "total_phenols": ["flavanoids", "nonflavanoid_phenols", "proanthocyanins"], "flavanoids": [], "nonflavanoid_phenols": [], "proanthocyanins": [], "color_intensity": ["flavanoids", "proanthocyanins", "total_phenols"], "hue": ["color_intensity"], "od280/od315_of_diluted_wines": ["flavanoids", "total_phenols"], "proline": ["alcohol", "total_phenols"],}name_to_idx = {n: i for i, n in enumerate(attribute_names)}dag = { name_to_idx[child]: [name_to_idx[p] for p in parents] for child, parents in wine_dag_by_name.items()}model_unsupervised = unsupervised.TabPFNUnsupervisedModel( tabpfn_clf=TabPFNClassifier(n_estimators=3), tabpfn_reg=TabPFNRegressor(n_estimators=3),)experiment = unsupervised.experiments.GenerateSyntheticDataExperiment(task_type="unsupervised")results = experiment.run( tabpfn=model_unsupervised, X=torch.tensor(X, dtype=torch.float32), y=torch.tensor(y, dtype=torch.float32), attribute_names=attribute_names, temp=1.0, n_samples=X.shape[0] * 3, indices=list(range(X.shape[1])), dag=dag,)
The DAG must be acyclic. A ValueError is raised if a cycle is detected, with the cycle path included in the error message. Features listed with an empty parent list ([]) are generated first using only marginal information.